

Scoring for Optimization
Suppose you have a number of competing candidates, each of which can be ranked with a score, but it takes a little time to calculate each candidate’s score. You’re only interested in the top [latex]n[/latex] candidates. You want to come up with a scoring scheme where you can throw the extra candidates out of consideration earlier without sacrificing quality. Such is the problem of scoring and ranking suggestions in Ubiquity. What properties must such a scoring system have?
This blog post includes a lot of complex CSS-formatted graphs which may be best viewed in — what else? — Firefox. You may also want to access this blog post directly rather than through a planet.
| candidate 8 | ||
|---|---|---|
| candidate 2 | ||
| candidate 9 | ||
| candidate 3 | ||
| candidate 10 | CUTOFF | |
| candidate 5 | ||
| candidate 1 | ||
| candidate 7 | ||
| … |
One portion of the problem description above merits clarification: I define “without sacrificing quality” to mean that, if we did not throw out any candidates early and waited until all the scores are computed fully and accurately, we would still yield the same top [latex]n[/latex] winners. This already gives us the key insight towards an appropriate solution: we can only throw out candidates when we know that it has no further chance of making it up into top [latex]n[/latex] candidates.
Let’s get formal
Let’s call [latex]S_{i}(t)[/latex] the score of candidate [latex]C_{i}[/latex] at time [latex]t[/latex] in the derivation and we’ll assume that the score derivations are done in parallel with a unique origin ([latex]t=0[/latex]).1 We’ll use the notation [latex]S_{i}(\infty)[/latex] to represent the equilibrium or final score, equal to [latex]S_{i}(t)[/latex] for all [latex]t > [/latex] a certain [latex]t^{\prime}[/latex] which exists for each candidate. This function [latex]S_{i}[/latex] thus defines a [[time series]] for each candidate.
Given a set of candidates [latex]\left{C_1,C_2,\ldots,C_k\right}[/latex], we want to find the best subset of [latex]n[/latex] candidates; that is, [latex]\left{C_{i_1},C_{i_2},\ldots,C_{i_n}\right}[/latex] such that
 .
.
Approach 1: A Threshold Model
The key insight above would naturally give us what I call the threshold model. Here, we require the score sequences to be non-increasing: [latex]\forall_{t < t^{\prime}} S_{i}(t) < S_{i}(t^{\prime})[/latex]. This way, we can naturally throw out candidates which have reached below a certain threshold [latex]M[/latex] (or attained a certain level of badness, you might say) which we can then be sure will never recover.
For example, suppose the following diagram represents the scores of five different candidates after the first four time steps of the derivation. (The full gray bar marks the initial score ([latex]S_i(0)[/latex]) and the arrows indicate the successive score differentials.) The vertical line marks the threshold, [latex]M[/latex].
| candidate 1 | ||
|---|---|---|
| candidate 2 | ||
| candidate 3 | ||
| candidate 4 | ||
| candidate 5 | ||
| … |
We can tell after four steps that candidates 2 and 4, given that the score sequences are non-increasing, have no chance to finish their derivation with a score [latex]> M[/latex]. What is important to note, however, is that candidate 4 already had no chance of beating the threshold after three steps. There was no need to calculate the fourth derivation of the score of candidate 4 ([latex]S_{4}(4)[/latex]). In other words, after three steps, we could completely take candidate 4 out of the running and after another step, take candidate 2 out of the running.
| [latex]t=2[/latex] | [latex]t=3[/latex] | [latex]t=4[/latex] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
→ |
|
→ |
|
→ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
This non-decreasing score approach was used in Ubiquity Parser 2 until just recently, and you can in fact still play with it on the online Ubiquity Parser TNG demo. In that version, every parse started with an initial score of 1 and every score factor would be a value between 0 and 1. Every score factor was multiplied onto the previous score throughout the derivation, making it trivially non-increasing.
The problem with this approach is how to choose a smart threshold and that, given a constant threshold, you may get a different number of results for every different candidate set (i.e. parser query). If your score indicates a meaningful value with an a priori specified target of acceptable values, having a threshold makes sense. In the case of Ubiquity, however, the interface expects a certain number of suggestions to be returned.2 If we plan to display five suggestions but the parser only returns four, even though there were other candidates, there must be a very good reason and justification for that threshold value.
Approach 2: Raising the Bar
The problem with Approach 1 was that there was no way of guaranteeing that we would yield our predefined [latex]n[/latex] winning candidates. Even if at some point in the derivation we are left with [latex]n[/latex] candidates still above the threshold, as the only restriction we have is that our score series are non-increasing, there is still a possibility that those remaining [latex]n[/latex] candidates’ scores will drop below [latex]M[/latex] later in the derivation.
We must instead at some point in the derivation identify (a) a set of at least [latex]n[/latex] candidates which will not get “worse” in the derivation and (b) candidates which have no chance of overtaking the (a) candidates. In this situation we can safely throw out the (b) candidates.
One way to do this is to require that all the scores [latex]S_{i}(t)[/latex] are bounded and non-decreasing. By virtue of being non-decreasing, our top candidates at any point in our derivation will never get “worse” afterwards, satisfying condition (a). If relatively early in the computation we can compute a bound [latex]B_i[/latex], we can identify candidates which will never surpass the top candidates in group (a) above, satisfying condition (b).
In the example below, [latex]n=2[/latex] and the thin bars mark the upper bounds [latex]B_i[/latex]. At [latex]t=1[/latex] we can identify candidate 2 and 4 as being our top two candidates. Note that there is one candidate, candidate 5, whose upper bound [latex]B_5[/latex] is less than both [latex]S_2(1)[/latex] and [latex]S_4(1)[/latex]. By definition [latex]S_5(\infty) \leq B_5[/latex] and because the scores are non-decreasing [latex]S_2(1) \leq S_2(\infty)[/latex] and [latex]S_4(1) \leq S_4(\infty)[/latex]. Therefore
 and
and 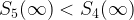
and we can thus throw out candidate 5 at this point. By the same logic, after [latex]t=2[/latex] we can throw candidate 2 out of the running.
| [latex]t=1[/latex] | [latex]t=2[/latex] | [latex]t=3[/latex] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
→ |
|
→ |
|
→ | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Calling this the “raising the bar” method refers to the fact that, at any particular time [latex]t[/latex], the “bar” is [latex]min\left(\left{\mbox{the }n\mbox{ greatest }S_{i}(t)\mbox{ values}\right}\right)[/latex] and every other candidate must have an upper bound [latex]B_j[/latex] greater than the bar in order to not be thrown out of consideration. This “bar” itself is, together with the component scores, non-decreasing, decreasing the number of surviving candidates over time.
In the case of the Ubiquity parser we could build such a non-decreasing and bounded scoring model by using an additive model. As the main component of parser scoring is how well the parsed arguments match the verbs’ specified nountypes, we could simply add up all the confidence scores of each nountype suggestion, each of which are a value between 0 and 1. This would trivially be non-decreasing. As each parse has a finite and known number of parsed arguments, we could easily determine a bound as well. For example, say a parse [latex]S_0[/latex] has two arguments. Before we check each of the nountypes’ match scores, we already know that [latex]S_0(\infty) \leq 2 = B_0[/latex].
Unfortunately, there are also other factors which we would like to consider in our parses which may not fit into this non-decreasing model so easily…
Approach 2’: The Rising Sun Model3
One problem with both of the previous approaches is that it requires that the scoring schemes be either non-increasing or non-decreasing across the derivation. There are many situations, however, where you would want different factors to affect the score both positively and negatively. In the case of the Ubiquity parser, here are some different factors which could be good positive and negative score factors in computing the score of each parse.
| positive factors | negative factors |
|---|---|
| the verb’s specified nountype matching the argument noun well | having to suggest the verb |
| the verb in the input matching the verb well | multiple arguments parsed for a single semantic role |
| the verb being used often | the verb missing some arguments |
As we see, there are both positive and negative factors which we hope to consider in scoring our possible Ubiquity parses. They key to making this work is by noting that Approach 2 only requires that the scoring series be bounded and non-decreasing after a certain known time in the derivation. For example, even if a parse involves a number of decreases early in the parse derivation, if after a certain point we can be certain that it is non-decreasing and bounded, we can simply use that bound and start eliminating poor candidates at that time (in this example, after [latex]t=2[/latex]).
| 5 | 10 | ||||||||||||
This is very much possible in the Ubiquity parser as, given the Ubiquity Parser 2 design, the negative factors such as whether the parse has a verb from the input or not (step 2), whether multiple arguments are identified with the same semantic role (step 4), and how many of the verb’s arguments are in the input (step 4) can be identified early on in the derivation, all before the very computationally intensive step of nountype detection (step 7) and argument suggestion (step 8). In this way, we can front-load all the negative factors in scoring and continue to use a version of Approach 2 to optimize our parsing.
We can moreover make the effect of the negative factors be felt across the entire derivation by figuring the negative factors into a factor between 0 and 1 and multiplying it onto each of the positive factors being added. In other words, we can compute all the negative factors into a single score multiplier [latex]\mu_i \in [0,1][/latex] earlier in the derivation and then afterwards when adding up each of the positive factors simply applying that score multiplier to the score derivation:
This model is what is going on under the hood in Ubiquity Parser 2. The Parser.Parse class has a property called .scoreMultiplier which contains the score multiplier [latex]\mu_i[/latex] as described above. A method called .getMaxScore() is implemented in addition to .getScore() so that, even before all of the nountype suggestion scores have been computed (e.g., in the case of asynchronous suggestions) .getMaxScore() can be used as an upper bound [latex]B_i[/latex] and compared to the in-progress scores of other candidates and lower candidates can thus be taken out of consideration earlier in the parse process.
Conclusion
In this blog post I’ve laid out a few different iterations of approaches I’ve thought of on the problem of scoring and ranking Ubiquity suggestions in a smart way. While some of the basic mechanisms of front-loading the negative factors into a scoreMultiplier and the computation of the maxScore (or upper bound) have been implemented, the actual optimization algorithm described here of removing parses from consideration earlier in the parser query has yet to be implemented in Ubiquity Parser 2 and I look forward to seeing it in action. In addition, there are surely factors I haven’t considered in the scoring or further tricks to improve the optimized scoring algorithm. I’d love to get your feedback and ideas on this topic. Thanks!
-
In the case of Ubiquity Parser 2, we’ll let the “time” values [latex]t[/latex] refer to the “steps” in the derivation, as laid out in the Ubiquity Parser 2 design. Note that these “steps” are currently done in parallel across all candidates in the current architecture, making the “time” analogy legitimate. I will thus use integer time values here, making this a [[discrete-time]] model. ↩
-
Every Ubiquity parser query takes as a parameter the maximum number of suggestions to be returned. See the latest parser query interface proposal for details on this interface. ↩
-
This naming is an homage to the [[rising sun lemma]] of [[Frigyes Riesz]] which uses a similar logic. The apparent connection to the fact that I am Japanese is purely coincidental. ↩