

Judging Noun Types
Introduction
Different arguments are classified into different kinds of nouns in Ubiquity using noun types.[^1] For example, a string like “Spanish” could be construed as a language, while “14.3” should not be. These kinds of relations are then used by the parser to introduce, for example, language-related verbs (like translate) using the former argument, and number-related verbs (like zoom or calculate) based on the latter. Ubiquity nountypes aren’t exclusive—a single string can count as valid for a number of different nountypes and in particular the “arbitrary text” nountype (noun_arb_text) will always accept any string given.
In addition to the [various built-in nountypes][1], Ubiquity lets command authors [write their own nountypes][2] as well.
The functions of a noun type
Nountypes have two functions: the first is accepting and suggesting suggestions and the second is scoring.
Accepting and suggesting
Nountypes don’t just have to accept the exact string they were given—they can also return suggestions which are based on that input. For example, the noun_type_language can take the input “span” and return “Spanish.” A nountype can return multiple suggestions which may or may not include the trivial suggestion, i.e. the original input as is. If there is no way that that input could possibly be part of an accepted value, it should return no suggestions, i.e. [].[^3]
Scoring
Ubiquity 0.5 with Parser 2 introduced the notion of a nountype suggestion score. For example, two different nountypes can accept the same input, but with different scores. Scores range from 0 to 1 where 1 is a perfect or exact suggestion and 0.1 or so is a very very improbable suggestion.[^2] These scores are used in the [scoring of parses][3]. Because verbs specify certain nountypes for each of their arguments, the scores that individual nountypes return for each argument are a crucial component of the scoring algorithm and can even determine whether a parse is returned or not.
With this in mind, you may be tempted to make your nountype return a score of 1 on any input so your verb will show up in the suggestions highly. While this would work, it will only act to make your verb annoying and a poor Ubiquity citizen. Appropriate scores must be given to noun suggestions, with higher values reflecting confidence and lower values reflecting imprecision. But how exactly do you figure out what’s an appropriate value?
Judging nountypes with the Nountype Tuner
The Nountype Tuner is a new tool I’ve been building to help both Ubiquity core developers and command authors to check their nountypes against others and to “tune” their behavior and scores. The nountype tuner will take your input and throw it against all of the nountypes referenced in your active verbs and display the suggestions returned with their scores. You can think of it as [the Playpen][4]’s little sister.
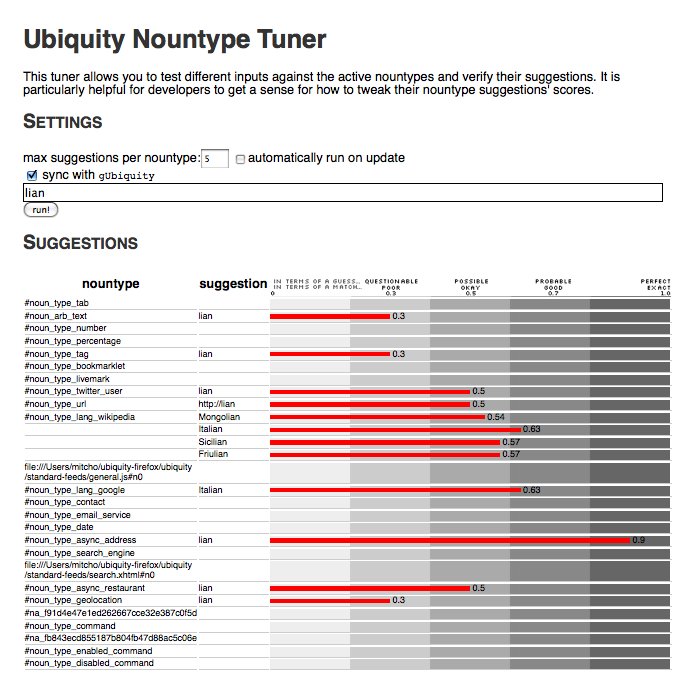
The Nountype Tuner can be found at <chrome://ubiquity/content/tuner.html>, though I am pretty sure it is broken in Ubiquity 0.5 and 0.5.1. It has been fixed now and I will make sure it’s in good shape for 0.5.2.
The heart and soul of the Nountype Tuner is this scale:
This scale tells you, in plain English, what different scores represent and correspond to, in two sets of vocabulary: “in terms of a guess” and “in terms of a match.” While still subjective, this scale helps developers just different input/output pairs and their scores. For example, “lian” → “http://lian” is given 0.5, so it’s an okay guess or a possible match… does that seem right to you? Or “lian” → “Italian” being between “okay” and “good.” Appropriate? We can look at such statements, decide how we feel about them, and tweak if necessary.
Good nountype scores have roots

CC-BY Aaron Escobar
…not that kind of root, but more like [this kind of root][5]… let me explain…
When comparing the scores that individual nountypes return for different inputs, we must compare those scores within the same nountype’s family of suggestions to see if higher scores truly correspond to higher confidence. For example, the language nountype should give the suggestion “French” for both the inputs “f” and “fren,” but the scores of these suggestions should be different—i.e. the score of “f” → “French” should be much lower than the score for “fren” → “French,” reflecting the additional informational value. We refer to this relation of the scores of successive prefixes of a single suggestion all returning that same suggestion as the score curve and in general it should be non-decreasing.[^4]
One could say the most trivial score function then is the linear one. For a series of converging prefixes of the same suggestion (“Dutch”), under a linear approach we could naively let the score be (length of the input)/(length of the suggestion), as below:
the linear model
| input | d | du | dut | dutc | dutch |
|---|---|---|---|---|---|
| output | Dutch | Dutch | Dutch | Dutch | Dutch |
| score | 0.2 | 0.4 | 0.6 | 0.8 | 1 |
</center>
This linear model is represented below by the black line.
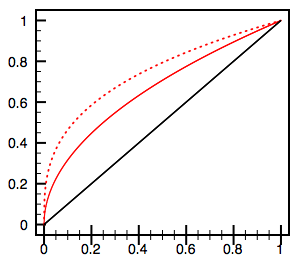
The problem with the linear model is that earlier transitions (additional keystrokes) add more information than the later ones. Once we’ve entered “dutc,” after all, we would like to be pretty darn sure that we mean “Dutch,” so the score difference between “dutc” and “dutch” should be less than the score difference between, say, “d” and “du.” We want a score curve that looks more like the solid or dotted red lines above.
For this reason, I strongly advocate the incorporation of an nth-root in the score computation. Nth-rooted score functions over [0,1] have the feature that they are increasing but also that earlier transitions affect the score more than later ones, which is exactly what we’d like to see. (The solid red line above is x^1/2 and the dotted one is x^1/3.)
Conclusion
Properly tuning both the built-in nountypes and custom nountypes is crucial to producing more accurate and relevant parse suggestions. I’ll be using the principles and criteria laid out above, combined with the new Nountype Tuner, to tune the built-in nountypes (trac #746) in the coming days in preparation for our 0.5.2 release. I invite you to use the Nountype Tuner in 0.5.2 to tune your custom nountypes as well.
Or, as I often write them, “nountypes.”
Note that I didn’t just say “if the input is not an accepted value…” That’s because, based on the left-to-right nature of text input, an argument may later become a valid input of a certain nountype with a few more keystrokes. For example, if we had a URL nountype which accepted “http://mitcho.com” but not “http://mitcho”, any command which took this nountype would not show up in the suggestions while we were typing out “http://mitcho”… but would suddenly appear when we completed the “.com”. The best practice here is to suggest a valid value for the initial “http://mitcho”, like “http://mitcho.com”.
(In reality, I should have said “initial-to-later nature” to be fair to right-to-left languages, but you get the idea. Speaking of which, serious consideration of Ubiquity in right-to-left languages is long overdue.)
In reality, due to the way parses are scored and the fact that noun_arb_text accepts anything with score 0.3, a suggestion with score below 0.3 is probably not worth even giving out. Notable exceptions are for custom noun types which are used in commands which take multiple arguments… in these cases, even scores below 0.3 could add up and overtake a noun_arb_text parse, but it’s rare.
The idea that successively longer inputs should yield successively higher scores only makes sense (1) when they are converging on the same suggestion output and (2) when these are truly suggestions, not just acceptances. For nountypes which accept the input verbatim, suggestion scores need not increase… for example “1” is just as good a “number” as “1234” is, so both of their respective suggestions, “1” and “1234” could be given the same score.
Unfortunately the Nountype Tuner currently only compares the suggestions of one input across a number of nountypes, not a number of inputs across the same nountype. In the future I’d like to make the Nountype Tuner be able to produce these sorts of score curves as well.