

Stamping PDFs in bulk
I recently put the program and abstracts online for the GLOW in Asia conference that we’re hosting in Singapore next February. In my experience, conference abstract PDFs easily come up on web searches and you want it to be immediately obvious whose work it is. Some conferences ask for updated abstracts with author names, but I didn’t want to deal with that. I instead chose to programmatically “stamp” each abstract PDF with the author names. Here are my notes on how I did that.
Adding text to a single PDF
First, I had to figure out how to add some text to a PDF from the command line. I followed these useful instructions. For me, this involved installing the enscript utility (which I did using Homebrew: brew install enscript), which can create simple PostScript from plain text, and PDFtk server, which is a neat command line package for manipulating PDFs. The PDFtk website doesn’t link to the latest build but I found some discussion which helpfully posted the link to the latest build which installed cleanly on Sierra.
With these installed, you can add a line of text to the top of an existing PDF as follows:
echo "text to add" | enscript -B -f Helvetica12 -o- | ps2pdf - | pdftk in.pdf stamp - output out.pdf
where in.pdf is the original PDF and out.pdf is what will be written. I played around briefly with font options, but Helvetica 12 looked fine for my purposes. You’ll notice that I’ve done nothing to specify where the text should be stamped on the PDF. While this can probably be controlled (probably by learning some PostScript), the default output was good enough so I went with it.
(I’m not thrilled about relying on this free but closed-source PDFtk tool, and perhaps that step will stop working with future OS updates… If you know of another way to stamp PDFs from the command line, please do share!)
Once I figured this part out, now I just needed to write a quick script to automate the process of applying this to the dozens of PDFs that I wanted to put online.
Programmatically adding text to multiple PDFs
What you get from EasyChair is a folder full of PDFs which are (or should be) anonymous and are organized by EasyChair ID.

I created a csv file with three columns:
- EasyChair ID number (to find the right abstract PDF)
- Desired filename (lowercased family names with hyphens, using -etal for more than two authors)
- Author names
I easily pulled columns 1 and 3 from the EasyChair website and quickly added in the second column. All of these fields are in plain text. Here’s what that looked like:
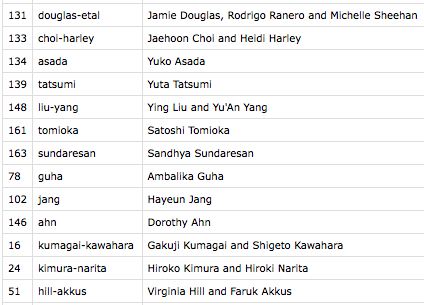
I wrote this python script which takes such a csv file, goes to find the appropriate PDF from the folder full of EasyChair abstracts, stamps the author names and “GLOW in Asia XI” on it, and saves it into another folder with the desired file name. In a matter of seconds, I had a folder full of de-anonymized abstracts, which I then put online:
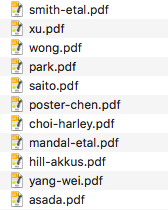
The results
You can see the resulting PDFs by looking at some of the abstracts on the the GLOW in Asia program. The results aren’t beautiful — for some abstracts, the placement of the text isn’t very pretty, and it definitely has a “robotically stamped” quality — but it did save me a heck of a lot of time.